Строка – это тип данных, состоящий из последовательности символов. Строковые константы могут быть заключены в двойные или одинарные кавычки. В Python строки имеют тип, называемый str
Все символы между открывающим разделителем и соответствующим закрывающим разделителем являются частью строки:
Все символы между открывающим разделителем и соответствующим закрывающим разделителем являются частью строки:
print("Это строка") # напечатает в консоль: Это строка
print(type("Это строка")) # напечатает в консоль: <class 'str'>
print('Это тоже строка') # напечатает в консоль: Это тоже строка
print(type('И я тоже строка')) # напечатает в консоль: <class 'str'>Строка в Python может содержать столько символов, сколько вы пожелаете. Единственное ограничение – это ресурсы памяти вашего компьютера. Строка также может быть пустой:
s = ''Что делать, если вы хотите включить символ кавычки как часть самой строки? Первое, что приходит в голову: попробовать что-то подобное:
print('Эта строка включает одинарную (') кавычку')
# мы получим ошибку: SyntaxError: invalid syntaxКак вы видите – эта конструкция не работает. Строка в этом примере открывается одинарной кавычкой, поэтому Python предполагает, что следующая одинарная кавычка, заключенная в круглые скобки, которая должна была быть частью строки, является закрывающим разделителем. Заключительная одинарная кавычка в этом случае является случайной и вызывает синтаксическую ошибку.
Если вы хотите включить в строку кавычку, самый простой способ – разделить строку другим типом кавычки. Если строка должна содержать одинарную кавычку, заключите ее в двойные кавычки и наоборот:
Если вы хотите включить в строку кавычку, самый простой способ – разделить строку другим типом кавычки. Если строка должна содержать одинарную кавычку, заключите ее в двойные кавычки и наоборот:
print("Эта строка включает одинарную (') кавычку")
print('Эта строка включает двойную (") кавычку')Экранирующие (escape) символы
Иногда вы можете захотеть, чтобы Python интерпретировал символ или последовательность символов в строке по-другому.
Вы можете сделать это с помощью символа обратной косой черты (\). Символ обратной косой черты в строке указывает на то, что один или несколько следующих за ним символов должны быть обработаны особым образом.
Ниже приведена таблица escape-последовательностей, которые заставляют Python подавлять обычную интерпретацию символа в строке.
Примеры
print("Символ\tтабуляции")
''' напечатает в консоль:
Символ табуляции
'''
print("Символ\n переноса строки")
''' напечатает в консоль:
Символ
переноса строки
'''Манипуляции со строками
В приведенных ниже разделах рассматриваются операторы, методы и функции, доступные для работы со строками.
Строковые операторы
Оператор конкантенации строк +
Этот оператор объединяет строки. Он возвращает строку, состоящую из соединенных вместе операндов, как показано ниже:
s = 'Я'
t = ' пошел'
u = ' в магазин'
print(s + t + u)
''' напечатает в консоль:
Я пошел в магазин
'''Оператор мультипликации строк *
Этот оператор создает несколько копий строки.
s = 'Слово.'
print(s * 3)
''' напечатает в консоль:
Слово.Слово.Слово.
'''
print(2 * s)
''' напечатает в консоль:
Слово.Слово.
'''Оператор in
Python также предоставляет оператор вхождения подстроки в строку. Оператор in возвращает значение True, если первый операнд содержится во втором, и значение False в противном случае:
s = 'школа'
print(s in 'Это моя школа') # напечатает True
print(s in 'Это мой дом') # напечатает FalseВстроенные функции для работы со строками
Python предоставляет множество функций, которые встроены в интерпретатор и всегда доступны. Вот некоторые из них, которые работают со строками:
print(ord('a')) # напечатает 97
print(chr(97)) # напечатает a
print(len("Математика")) # напечатает 10
print(str(18.5)) # напечатает '18.5'Индексация строк
Часто в языках программирования к отдельным элементам набора данных можно получить прямой доступ, используя числовой индекс или ключевое значение. Этот процесс называется индексированием.
В Python строки представляют собой упорядоченные последовательности символов и, следовательно, могут быть проиндексированы. Доступ к отдельным символам в строке можно получить, указав имя строки, за которым следует число в квадратных скобках [].
Индексация строк в Python начинается с 0: первый символ в строке имеет индекс 0, следующий – индекс 1 и так далее. Индекс последнего символа будет равен длине строки минус единица.
Например, схема индексов строки ‘пайтон‘ будет выглядеть следующим образом:
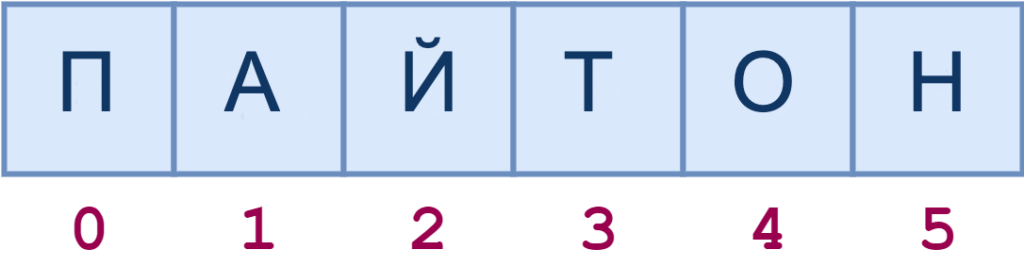
Доступ к отдельным символам можно получить по индексу следующим образом:
s = 'пайтон'
print(s[0]) # напечатает 'п'
print(s[2]) # напечатает 'й'
print(s[6]) # IndexError: string index out of rangeПопытка индексирования за пределами конца строки приводит к ошибке.
Индексы строк также могут быть указаны с отрицательными числами. В этом случае индексация происходит с конца строки в обратном направлении: -1 относится к последнему символу, -2 – к предпоследнему символу и так далее. Вот та же схема, показывающая как положительные, так и отрицательные индексы в строке ‘пайтон‘:
Индексы строк также могут быть указаны с отрицательными числами. В этом случае индексация происходит с конца строки в обратном направлении: -1 относится к последнему символу, -2 – к предпоследнему символу и так далее. Вот та же схема, показывающая как положительные, так и отрицательные индексы в строке ‘пайтон‘:
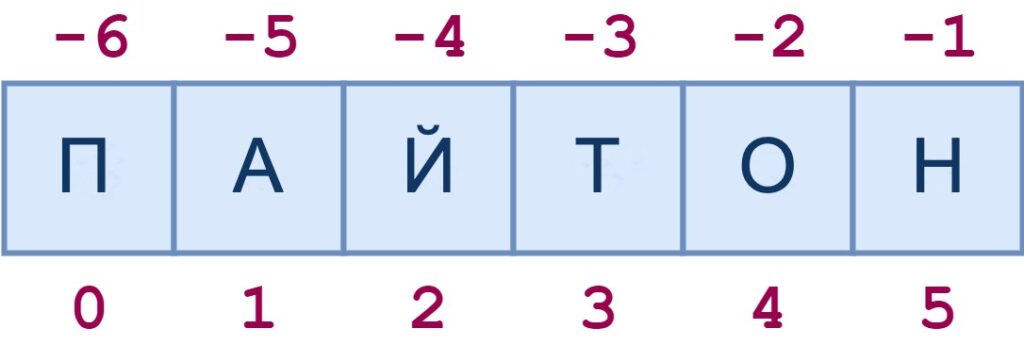
Вот несколько примеров отрицательной индексации:
s = 'пайтон'
print(s[-2]) # напечатает 'о'
print(s[-6]) # напечатает 'п'Срезы строк (String Slicing)
Python также допускает форму синтаксиса индексирования, которая извлекает подстроки из строки, известную как нарезка строк. Если s является строкой, выражение вида s[m:n] возвращает часть s, начинающуюся с позиции m, и до позиции n, но не включая ее:
s = 'пайтон'
print(s[0:3]) # напечатает 'пай'Если вы опустите первый индекс, срез начнется с начала строки. Таким образом, s[:m] и s[0:m] эквивалентны:
s = 'пайтон'
print(s[:3]) # тоже напечатает 'пай'Отрицательные индексы также можно использовать в срезах. -1 относится к последнему символу, -2 – к предпоследнему и так далее, точно так же, как при простом индексировании.
s = 'пайтон'
print(s[-5:-2]) # напечатает 'айт'Указание шага в срезах строк
Существует еще один вариант синтаксиса срезов, который следует обсудить. Добавление дополнительного двоеточия (:) и третьего индекса обозначает шаг, который указывает, на сколько символов нужно перейти после извлечения каждого символа в срезе.
Например, для строки ‘PYTHON‘ фрагмент 0:6:2 начинается с первого символа и заканчивается последним символом (целой строкой), и каждый второй символ пропускается. Это показано на следующей схеме:
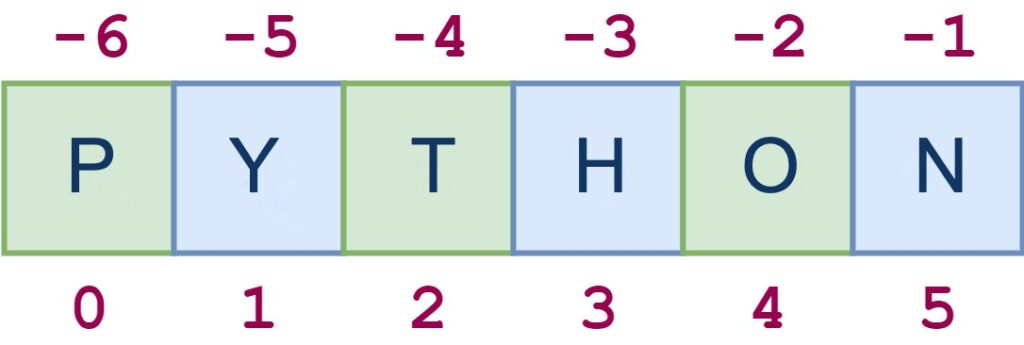
s = 'PYTHON'
print(s[0:6:2]) # напечатает 'PTO'Интерполяция переменных в строку
В Python версии 3.6 был введен новый механизм форматирования строк. Эта функция официально называется форматированным строковым литералом, но чаще всего ее называют псевдонимом f-string.
Одна простая функция f-string, которую вы можете начать использовать сразу же, – это интерполяция переменных. Вы можете указать имя переменной непосредственно в литерале f-string, и Python заменит это имя соответствующим значением.
Например, предположим, что вы хотите отобразить результат арифметического вычисления. Вы можете сделать это с помощью простого оператора print(), разделяя числовые значения и строковые литералы запятыми:
name = 'Ivan'
surname = 'Petrov'
print('Name:', name, 'surname:', surname)
# напечатает 'Name: Ivan surname: Petrov'Но, это громоздко. Чтобы выполнить то же самое, нужно использовать f-строку:
- Укажите либо строчную f, либо прописную F непосредственно перед начальной кавычкой строкового литерала. Это укажет Python, что это f-строка вместо стандартной строки.
- Укажите любые переменные, которые будут интерполированы, в фигурных скобках {}.
name = 'Ivan'
surname = 'Petrov'
print(f'Name: {name} surname: {surname}')
# напечатает 'Name: Ivan surname: Petrov'Модификация строк
Строки – это один из типов данных, которые Python считает неизменяемыми, то есть не подлежащими изменению.
>>> s = 'Питон'
>>> s[2] = 'у'
Traceback (most recent call last):
File "<pyshell#40>", line 1, in <module>
s[2] = 'у'
TypeError: 'str' object does not support item assignmentПо правде говоря, на самом деле нет особой необходимости изменять строки. Обычно вы можете легко выполнить то, что хотите, сгенерировав копию исходной строки, в которой есть нужное изменение. Есть много способов сделать это в Python. Вот несколько вариантов:
s = 'Питон'
s = s[:1] + 'у' + s[2:]
print(s) # напечатает 'Путон'
s = 'Питон'
s = s.replace('и', 'у')
print(s) # напечатает 'Путон'Встроенные строковые методы
Python – это объектно-ориентированный язык. Каждый элемент данных в программе Python является объектом. Вы также знакомы с функциями: вызываемыми процедурами, которые вы можете вызывать для выполнения определенных задач.
Методы аналогичны функциям. Метод – это специализированный тип вызываемой процедуры, который тесно связан с объектом. Как и функция, метод вызывается для выполнения отдельной задачи, но он вызывается для определенного объекта и имеет информацию о своем целевом объекте во время выполнения.
Синтаксис для вызова метода для объекта следующий:
obj.foo(<args>)Выше вызывается метод .foo() для объекта obj. <args> указывает на аргументы, переданные методу (если таковые имеются).
Case методы
Методы в этой группе выполняют преобразование регистра в целевой строке.
s.capitalize()
s.capitalize() возвращает копию строки s с первым символом, преобразованным в верхний регистр, и всеми остальными символами, преобразованными в нижний регистр:
>>> s = 'я Люблю ПиТон'
>>> s.capitalize()
'Я люблю питон's.lower()
s.lower() возвращает копию s со всеми буквенными символами, преобразованными в нижний регистр:
>>> 'Я Учу Питон 3'.lower()
'я учу питон 3's.swapcase()
s.swapcase() возвращает копию s с символами верхнего регистра, преобразованными в нижний регистр, и наоборот:
>>> 'Hello World'.swapcase()
'hELLO wORLD's.title()
s.title() возвращает копию s, в которой первая буква каждого слова преобразуется в верхний регистр, а остальные буквы – в нижний:
>>> 'hello world'.title()
'Hello World's.upper()
s.upper() возвращает копию s со всеми символами, преобразованными в верхний регистр:
>>> 'Пайтон'.upper()
'ПАЙТОН'Поиск и замена строк
Эти методы предоставляют различные средства поиска в целевой строке указанной подстроки.
Каждый метод в этой группе поддерживает необязательные аргументы <start> и <end>. Действие метода ограничено частью целевой строки, начинающейся с позиции символа <start> и продолжающейся до, но не включающей позицию символа <end>. Если <start> указано, но <end> нет, метод применяется к части целевой строки от <start> до конца строки.
s.count([, [, ]])
s.count(<sub>) возвращает количество неперекрывающихся вхождений подстроки <sub> в s:
>>> 'один два три один четыре один'.count('один')
3s.endswith([, [, ]])
s.endswith(<суффикс>) возвращает True, если s заканчивается указанным <суффиксом>, и False в противном случае:
>>> 'Java'.endswith('va')
True
>>> 'Java'.endswith('ton')
Falses.find([, [, ]])
Вы можете использовать .find(), чтобы узнать, содержит ли строка Python определенную подстроку. s.find(<sub>) возвращает наименьший индекс в s, где найдена подстрока <sub>:
>>> 'one two nine'.find('two')
4Этот метод возвращает значение -1, если указанная подстрока не найдена
s.index([, [, ]])
Этот метод идентичен .find(), за исключением того, что он вызывает исключение, если <sub> не найден, а не возвращает -1:
>>> 'one two nine'.index('eleven')
Traceback (most recent call last):
File "<pyshell#0>", line 1, in <module>
'one two nine'.index('eleven')
ValueError: substring not founds.rfind([, [, ]])
s.rfind(<sub>) возвращает наибольший индекс в s, где найдена подстрока <sub>:
>>> 'one two nine two'.rfind('two')
13
s.rindex([, [, ]])
Этот метод идентичен .rfind(), за исключением того, что он вызывает исключение, если <sub> не найден, а не возвращает -1:
>>> '11 22 33'.rindex('44')
Traceback (most recent call last):
File "<pyshell#1>", line 1, in <module>
'11 22 33'.rindex('44')
ValueError: substring not founds.startswith([, [, ]])
s.startswith(<суффикс>) возвращает True, если s начинается с указанного <суффикса>, и False в противном случае:
>>> 'scala'.startswith('sc')
True
>>> 'scala'.startswith('py')
FalseКлассификация символов
Методы в этой группе классифицируют строку на основе содержащихся в ней символов.
s.isalnum()
s.isalnum() возвращает значение True, если s не пустая и все ее символы являются буквенно-цифровыми (либо буква, либо цифра), и значение False в противном случае:
>>> 'xyz123'.isalnum()
True
>>> '100$'.isalnum()
False
>>> ''.isalnum()
Falses.isalpha()
s.isalpha() возвращает значение True, если s не пустая и все ее символы являются буквенными, и значение False в противном случае
s.isdigit()
Вы можете использовать метод .isdigit() в Python, чтобы проверить, состоит ли ваша строка только из цифр. s.isdigit() возвращает True, если s не пустая и все ее символы являются числовыми цифрами, и False в противном случае
s.isidentifier()
s.isidentifier() возвращает True, если s является допустимым идентификатором Python в соответствии с определением языка, и False в противном случае
>>> 'val8'.isidentifier()
True
>>> '7free'.isidentifier()
False
>>> 'usd$32'.isidentifier()
Falses.islower()
s.islower() возвращает значение True, если значение s не пустое и все содержащиеся в ней буквенные символы являются строчными, в противном случае значение False. Неалфавитные символы игнорируются
s.isprintable()
s.isprintable() возвращает значение True, если значение s пусто или все содержащиеся в ней буквенные символы доступны для печати. Метод возвращает значение False, если s содержит хотя бы один непечатаемый символ. Неалфавитные символы игнорируются
>>> 'Hello \t World'.isprintable()
False
>>> 'Hello World'.isprintable()
True
>>> ''.isprintable()
True
>>> 'Newline \n'.isprintable()
Falses.isspace()
Определяет, состоит ли целевая строка из пробелов.
s.isspace() возвращает значение True, если значение s непустое и все символы являются пробелами, и значение False в противном случае
s.istitle()
Метод s.istitle() возвращает значение True, если s не пустая, первый буквенный символ каждого слова прописной, а все остальные буквенные символы в каждом слове строчные. В противном случае он возвращает значение False
>>> 'This Is A Title!'.istitle()
True
>>> 'This is a title!'.istitle()
Falses.isupper()
Определяет, являются ли буквенные символы целевой строки заглавными. Метод s.isupper() возвращает значение True, если значение s непустое и все содержащиеся в нем буквенные символы прописные, в противном случае значение False. Неалфавитные символы игнорируются.
Форматирование строк
s.center([, ])
Центрирует строку. Возвращает строку, состоящую из s, центрированную по ширине.
>>> 'new'.center(10)
' new 's.ljust([, ])
Выравнивает строку в поле по левому краю. s.ljust(<width>) возвращает строку, состоящую из s, выровненную по левому краю в поле по ширине width.
>>> 'new'.ljust(10)
'new 's.lstrip([])
Удаляет начальные символы из строки. s.lstrip() возвращает копию s с пробелами, удаленными с левого конца
>>> ' red green blue '.lstrip()
'red green blue '
>>> '\t\nred\t\ngreen\t\nblue'.lstrip()
'red\t\ngreen\t\nblue's.replace(, [, ])
Заменяет вхождения подстроки внутри строки. s.replace(<old>, <new>) возвращает копию s со всеми вхождениями подстроки <old>, замененной на <new>
>>> 'red green green red'.replace('red', 'blue')
'blue green green blue's.rjust([, ])
Выравнивает строку в поле по правому краю.
s.rjust(<width>) возвращает строку, состоящую из s, выровненную по правому краю по ширине width
>>> 'sky'.rjust(10)
' sky's.rstrip([])
s.rstrip() возвращает копию s с пробелами, удаленными с правого конца
>>> ' one two '.rstrip()
' one two'
>>> 'one\t\ntwo\t\none\t\n'.rstrip()
'one\t\ntwo\t\none's.strip([])
Удаляет пустые символы с левого и правого концов строки.
s.zfill()
Заполняет строку слева нулями.
>>> '51'.zfill(5)
'00051'Преобразования между строками и коллекциями
Методы этой группы делают преобразования между строками и коллекциями, либо соединяя объекты вместе, чтобы создать строку, либо разбивая строку на части.
Эти методы работают с iterables или возвращают их (общий термин Python для обозначения последовательной коллекции объектов).
s.join()
s.join(<iterable>) возвращает строку, полученную в результате объединения объектов в <iterable>, разделенных символом s.
>>> ', '.join(['one', 'two', 'three'])
'one, two, three's.partition()
Разделяет строку на основе разделителя. Возвращаемое значение представляет собой кортеж из трех частей, состоящий из
- Часть s, предшествующая <sep>
- сам <sep>
- Часть s, следующая за <sep>
>>> 'one.two'.partition('.')
('one', '.', 'two')
>>> 'one@@two@@three'.partition('@@')
('one', '@@', 'two@@three')
>>> 'one.two'.partition('@@')
('one.two', '', '')s.rpartition()
s.rpartition(<sep>) работает точно так же, как s.partition(<sep>), за исключением того, что s разделяется при последнем появлении <sep> вместо первого
s.splitlines([])
s.splitlines() разбивает s на строки и возвращает их в виде списка. Любой из следующих символов или последовательностей символов считается границей линии:
>>> 'red\ngreen\r\nblue\forange\u2028black'.splitlines()
['red', 'green', 'blue', 'orange', 'black']Заключение
В этом руководстве представлен подробный обзор множества различных механизмов, предоставляемых Python для обработки строк, включая строковые операторы, встроенные функции, индексирование, слайсы и встроенные методы.