Вы когда-нибудь задумывались, как Python обрабатывает ваши данные за кулисами? Как ваши переменные хранятся в памяти? Когда они удаляются?
В этой статье мы глубоко погрузимся во внутренности Python, чтобы понять, как он справляется с управлением памятью.
К концу этой статьи вы:
- Узнаете больше о низкоуровневых вычислениях, особенно в том, что касается памяти
- Поймете, как Python абстрагирует операции более низкого уровня
- Узнаете об алгоритмах управления внутренней памятью в Питоне
Понимание внутренних функций также даст вам лучшее представление о некоторых особенностях поведения Python. Надеюсь, вы также по-новому оцените Питон. Много логики происходит за кулисами, поэтому нужна гарантия, что ваша программа работает так, как вы ожидаете.
Память – это пустая книга
Представим память компьютера как пустую книгу, предназначенную для коротких рассказов. На страницах еще ничего не написано. Но, есть разные авторы. Каждому автору нужно немного места, чтобы написать свою историю.
Поскольку им не разрешается писать поверх друг друга, они должны быть внимательны, на каких страницах пишут. Прежде чем начать писать, они консультируются с менеджером книги. Затем менеджер решает, где в книге им разрешено писать.
Поскольку эта книга существует уже давно, многие рассказы в ней больше не актуальны. Когда никто не читает рассказы или не ссылается на них, они удаляются, чтобы освободить место для новых рассказов.
По сути, компьютерная память подобна этой пустой книге. На самом деле, обычно непрерывными блоками страниц памяти называют страницы фиксированной длины, так что эта аналогия вполне справедлива.
Авторы подобны различным приложениям или процессам, которым необходимо хранить данные в памяти. Менеджер, который решает, где авторы могут писать в книге, играет роль своего рода менеджера памяти. Человек, который удалил старые истории, чтобы освободить место для новых, является сборщиком мусора.
Управление памятью: от аппаратного к программному обеспечению
Управление памятью – это процесс, с помощью которого приложения считывают и записывают данные. Менеджер памяти определяет, куда поместить данные приложения. Поскольку объем памяти ограничен, как у страниц в нашей аналогии с книгой, менеджер должен найти немного свободного места и предоставить его приложению. Этот процесс предоставления памяти обычно называется выделением памяти.
С другой стороны, когда данные больше не нужны, их можно удалить или освободить. Но, освободить где и как? Откуда берется понятие памяти компьютера?
Когда вы запускаете свои программы на Python, где-то в вашем компьютере есть физическое устройство, хранящее данные. Однако существует множество уровней абстракции, через которые проходит код Python, прежде чем объекты действительно попадут в аппаратное обеспечение.
Одним из основных уровней над аппаратным обеспечением (таким как оперативная память или жесткий диск) является операционная система (ОС). Она принимает (или отклоняет) запросы на чтение и запись в память.
Над ОС есть приложения, одно из которых является реализацией Python по умолчанию (включено в вашу ОС или загружено с python.org) Управление памятью для вашего кода на Python осуществляется приложением на Python. В центре внимания этой статьи лежат алгоритмы и структуры, которые Python использует для управления памятью.
Реализация Python по умолчанию
Реализация Python по умолчанию, CPython, на самом деле написан на языке программирования C.
Когда я впервые услышал это, у меня снесло крышу. Язык, который написан на другом языке?! Ну, не совсем, но вроде того.
Язык Python определен в справочном руководстве, написанном на английском языке. Однако само по себе это руководство не так уж полезно. Вам все еще нужно что-то для интерпретации написанного кода на основе этих правил в руководстве.
Вам также нужно что-то для выполнения интерпретируемого кода на компьютере. Реализация Python по умолчанию удовлетворяет обоим этим требованиям. Он преобразует ваш код на Python в инструкции, которые затем запускает на виртуальной машине.
Python – это интерпретируемый язык программирования. Ваш код на Python фактически компилируется до более удобочитаемых инструкций, называемых байт-кодом. Эти инструкции интерпретируются виртуальной машиной при запуске вашего кода.
Вы когда-нибудь видели файл .pyc или папку __pycache__? Это байт-код, который интерпретируется виртуальной машиной.
Важно отметить, что существуют реализации, отличные от CPython. IronPython компилируется для запуска в среде Microsoft Common Language Runtime. Jython компилируется до байт-кода Java для запуска на виртуальной машине Java. Затем есть PyPy, но он заслуживает отдельной статьи, поэтому я просто упомяну его вскользь.
В этой статье мы сосредоточимся на управлении памятью, выполняемом реализацией Python по умолчанию – CPython.
Итак, CPython написан на C, и он интерпретирует байт-код Python. Какое это имеет отношение к управлению памятью? Ну, алгоритмы и структуры управления памятью существуют в коде CPython, в C. Чтобы понять управление памятью в Python, вы должны получить базовое представление о самом CPython.
CPython написан на C, который изначально не поддерживает объектно-ориентированное программирование. Из-за этого в коде CPython довольно много интересных дизайнов.
Возможно, вы слышали, что все в Python является объектом, даже такие типы, как int и str. Что ж, это верно на уровне реализации в CPython. Существует структура, называемая PyObject, которую использует любой другой объект в CPython.
PyObject, прародитель всех объектов в Python, он содержит только две вещи:
- ob_refcnt: счетчик ссылок
- ob_type: указатель на другой тип
Счетчик ссылок используется для сборки мусора. Также у вас есть указатель на фактический тип объекта. Этот тип объекта – просто еще одна структура, которая описывает объект Python (например, dict или int).
У каждого объекта есть свой собственный распределитель памяти для конкретного объекта, который знает, как получить память для хранения этого объекта. У каждого объекта также есть специфичное для объекта средство освобождения памяти, которое “освобождает” память, как только она больше не нужна.
Во всех этих фразах о выделении и освобождении памяти есть важный фактор. Память является общим ресурсом на компьютере, и могут произойти плохие вещи, если два разных процесса попытаются выполнить запись в одно и то же место в одно и то же время.
Глобальная блокировка интерпретатора (GIL)
GIL – это решение общей проблемы работы с общими ресурсами, такими как память в компьютере. Когда два потока пытаются изменить один и тот же ресурс одновременно, они могут наступать друг другу на пятки. Конечным результатом может быть беспорядок, когда ни один из потоков не получает того, что он хотел.
Еще раз рассмотрим аналогию с книгой. Предположим, что два автора упрямо решают, что теперь их очередь писать. Не только это, но и то, что они оба должны писать на одной странице книги в одно и то же время.
Каждый из них игнорирует попытку другого придумать рассказ и начинает писать на странице. Конечный результат – два рассказа друг на друге, что делает всю страницу совершенно нечитаемой.
Одним из решений этой проблемы является единая глобальная блокировка интерпретатора, когда поток взаимодействует с общим ресурсом (страница в книге). Другими словами, одновременно может писать только один автор.
GIL в Пайтоне блокирует весь интерпретатор, что означает, что другой поток не может начать работу. Когда CPython обрабатывает память, он использует GIL, чтобы гарантировать, что делает это безопасно.
У этого подхода есть свои плюсы и минусы, и GIL активно обсуждается в сообществе Python.
Сборка мусора в Питоне
Давайте вернемся к аналогии с книгой и предположим, что некоторые рассказы в книге становятся очень старыми. Никто больше не читает и не ссылается на них. Если никто не читает рассказы или не ссылается на них в своей работе, можно избавиться от них, для того, чтобы освободить место для нового рассказа.
Этот старый рассказ без ссылок можно сравнить с объектом в Python, количество ссылок на который упало до 0. Помните, что каждый объект в Python имеет счетчик ссылок и указатель на тип.
Количество ссылок может увеличиваться по разным причинам. Например, количество ссылок увеличится, если вы присвоите объект другой переменной:
numbers = [1, 2, 3, 4]
# количество ссылок = 1
numbers2 = numbers
# количество ссылок = 2Он также увеличится, если вы передадите объект в качестве аргумента:
total_sum = sum(numbers)Python позволяет вам проверять текущее количество ссылок на объект с помощью модуля sys. Вы можете использовать метод sys.getrefcount(numbers), но имейте в виду, что передача объекта в getrefcount() также увеличивает количество ссылок на 1.
В любом случае, если объект все еще должен находиться в вашем коде, количество его ссылок больше 0. Как только значение падает до 0, у объекта вызывается определенная функция очистки, которая “освобождает” память, чтобы другие объекты могли ее использовать.
Но, что значит “освободить” память и как ее используют другие объекты? Давайте перейдем к управлению памятью CPython.
Управление памятью в CPython
Мы собираемся глубоко погрузиться в архитектуру памяти и алгоритмы CPython, так что пристегнитесь.
Как упоминалось ранее, существуют уровни абстракции от физического оборудования до CPython. Операционная система (OS) абстрагирует физическую память и создает уровень виртуальной памяти, к которому приложения (включая Питон) могут получить доступ.
Менеджер виртуальной памяти для конкретной операционной системы выделяет часть памяти для процесса Python. Более темные серые поля на изображении ниже принадлежат процессу Python:

Python использует часть памяти для внутреннего потребления и не-объектной памяти. Другая часть предназначена для хранения объектов (int, dict и т. п.). Обратите внимание, что мы упростили схему. Если вы хотите получить полную картину, вы можете ознакомиться с исходным кодом CPython, где происходит все это управление памятью.
В CPython есть object allocator, который отвечает за выделение памяти в области объектной памяти. Именно в этом аллокаторе происходит большая часть волшебства. Он вызывается каждый раз, когда для нового объекта требуется выделить или удалить пространство.
Как правило, добавление и удаление данных для объектов Python, таких как list и int, не требует слишком большого количества ресурсов одновременно. Дизайн аллокатора настроен на стабильную работу с небольшими объемами данных одновременно. Он также старается не выделять память до тех пор, пока это не станет абсолютно необходимым.
Комментарии в исходном коде описывают аллокатор как “быстрый распределитель памяти специального назначения для небольших блоков, который будет использоваться поверх malloc общего назначения”. В данном случае malloc – это библиотечная функция C для выделения памяти.
Теперь мы рассмотрим стратегию распределения памяти CPython.
Области являются самыми большими блоками памяти и выровнены по границе страницы в памяти. Граница страницы – это граница непрерывного блока памяти фиксированной длины, используемого операционной системой. Python предполагает, что размер страницы системы составляет 256 килобайт.
В CPython есть object allocator, который отвечает за выделение памяти в области объектной памяти. Именно в этом аллокаторе происходит большая часть волшебства. Он вызывается каждый раз, когда для нового объекта требуется выделить или удалить пространство.
Как правило, добавление и удаление данных для объектов Python, таких как list и int, не требует слишком большого количества ресурсов одновременно. Дизайн аллокатора настроен на стабильную работу с небольшими объемами данных одновременно. Он также старается не выделять память до тех пор, пока это не станет абсолютно необходимым.
Комментарии в исходном коде описывают аллокатор как “быстрый распределитель памяти специального назначения для небольших блоков, который будет использоваться поверх malloc общего назначения”. В данном случае malloc – это библиотечная функция C для выделения памяти.
Теперь мы рассмотрим стратегию распределения памяти CPython.
Области являются самыми большими блоками памяти и выровнены по границе страницы в памяти. Граница страницы – это граница непрерывного блока памяти фиксированной длины, используемого операционной системой. Python предполагает, что размер страницы системы составляет 256 килобайт.
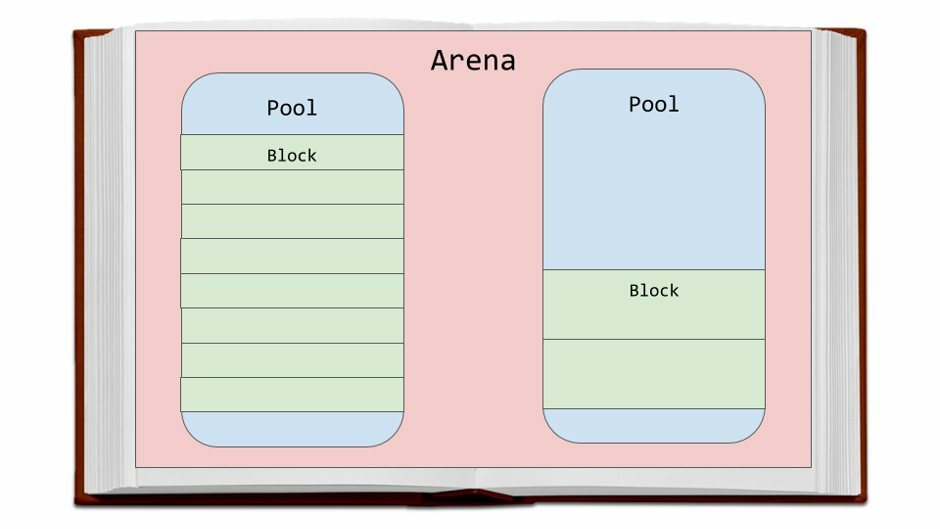
Внутри арен находятся пулы, которые представляют собой одну страницу виртуальной памяти (4 килобайта). Это похоже на страницы нашей книги. Эти пулы фрагментированы на более мелкие блоки памяти.
Все блоки в данном пуле имеют один и тот же size class. Size class определяет определенный размер блока, учитывая некоторый объем запрашиваемых данных. Приведенная ниже диаграмма взята непосредственно из комментариев к исходному коду:
Все блоки в данном пуле имеют один и тот же size class. Size class определяет определенный размер блока, учитывая некоторый объем запрашиваемых данных. Приведенная ниже диаграмма взята непосредственно из комментариев к исходному коду:
Например, если запрашивается 42 байта, данные будут помещены в блок размером 48 байт.
Пулы
Пулы состоят из блоков одного size class. Каждый пул поддерживает двусвязный список с другими пулами того же size class. Таким образом, алгоритм может легко найти доступное пространство для заданного размера блока, даже в разных пулах.
Список usedpools отслеживает все пулы, в которых есть некоторое пространство, доступное для данных для каждого size class. Когда запрашивается заданный размер блока, алгоритм проверяет список usedpools на наличие списка пулов для этого size class.
Сами пулы должны находиться в одном из 3 состояний: используемые, полные или пустые. Используемый пул имеет доступные блоки для хранения данных. Все блоки полного пула распределены и содержат данные. В пустом пуле не хранятся данные, и при необходимости блокам может быть присвоен любой size class.
Список пустых пулов отслеживает все пулы в пустом состоянии. Но когда используются пустые пулы?
Предположим, вашему коду требуется 8-байтовый фрагмент памяти. Если в usedpools нет пулов size class 8 байт, инициализируется новый пустой пул для хранения 8-байтовых блоков. Затем этот новый пул добавляется в список usedpools, чтобы его можно было использовать для будущих запросов.
Допустим, полный пул освобождает некоторые из своих блоков, потому что память больше не нужна. Этот пул будет добавлен обратно в список usedpools для его size class.

Как видно на схеме выше, пулы содержат указатель на свои “свободные” блоки памяти. В том, как это работает, есть небольшой нюанс. Этот аллокатор “стремится на всех уровнях (арена, пул и блок) никогда не прикасаться к фрагменту памяти, пока это действительно не понадобится”, согласно комментариям в исходном коде.
Это означает, что пул может содержать блоки в 3 состояниях. Эти состояния могут быть определены следующим образом:
Указатель freeblock указывает на односвязный список свободных блоков памяти. Другими словами, список доступных мест для размещения данных. Если требуется больше доступных свободных блоков, аллокатор получит несколько нетронутых блоков в пуле.
Поскольку диспетчер памяти делает блоки “свободными”, эти теперь свободные блоки добавляются в начало списка свободных блоков. Фактический список может не представлять собой непрерывные блоки памяти, как на первой схеме. Это может выглядеть примерно так, как показано ниже:
Это означает, что пул может содержать блоки в 3 состояниях. Эти состояния могут быть определены следующим образом:
- untouched: часть памяти, которая не была выделена
- free: часть памяти, которая была выделена, но позже стала “свободной” с помощью CPython и которая больше не содержит соответствующих данных
- allocated: часть памяти, которая фактически содержит соответствующие данные
Указатель freeblock указывает на односвязный список свободных блоков памяти. Другими словами, список доступных мест для размещения данных. Если требуется больше доступных свободных блоков, аллокатор получит несколько нетронутых блоков в пуле.
Поскольку диспетчер памяти делает блоки “свободными”, эти теперь свободные блоки добавляются в начало списка свободных блоков. Фактический список может не представлять собой непрерывные блоки памяти, как на первой схеме. Это может выглядеть примерно так, как показано ниже:

Арены
В аренах есть пулы. Эти пулы могут быть используемыми, полными или пустыми. Однако сами арены не имеют таких явных состояний, как пулы.
Вместо этого арены организованы в двусвязный список, называемый usable_arenas. Список отсортирован по количеству доступных свободных пулов. Чем меньше свободных пулов, тем ближе арена к началу списка.
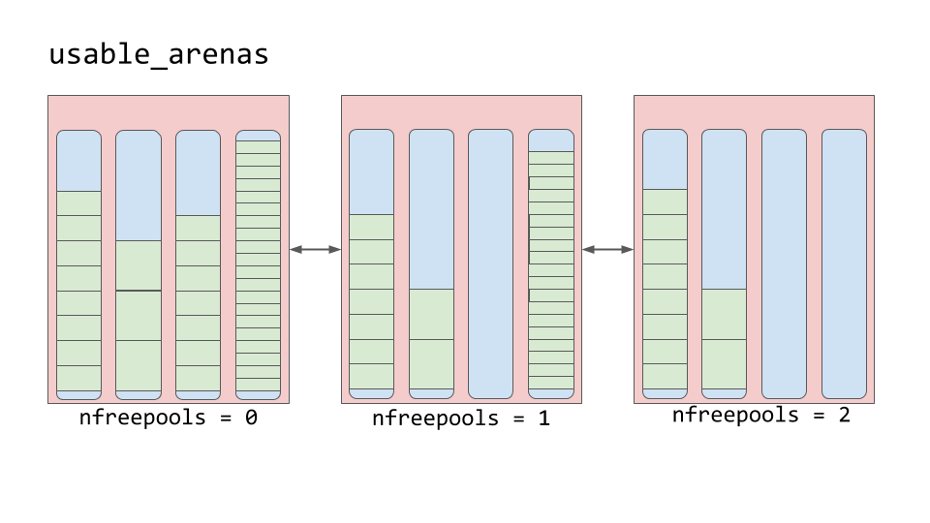
Это означает, что для размещения новых данных будет выбрана арена, наиболее заполненная данными. Но почему не наоборот? Почему бы не разместить данные там, где больше всего свободного места?
Это подводит нас к идее истинного освобождения памяти. Когда блок считается “свободным”, эта память фактически не освобождается обратно в операционную систему. Процесс Python сохраняет его выделенным и будет использовать позже для новых объектов. По-настоящему освобождая память, вы возвращаете ее в операционную систему для использования.
Арены – это единственное, что действительно может быть освобождено. Таким образом, само собой разумеется, что тем аренам, которые ближе к тому, чтобы освободиться, следует позволить освободиться. Этот фрагмент памяти может быть действительно освобожден, уменьшая общий объем памяти вашей программы на Python.
Заключение
Управление памятью является неотъемлемой частью работы с компьютерами. Python почти все это делает за кулисами.
Python абстрагирует множество сложных деталей. Это дает возможность работать на более высоком уровне, писать ваш код без головной боли, связанной с беспокойством о том, как и где хранятся все эти байты.